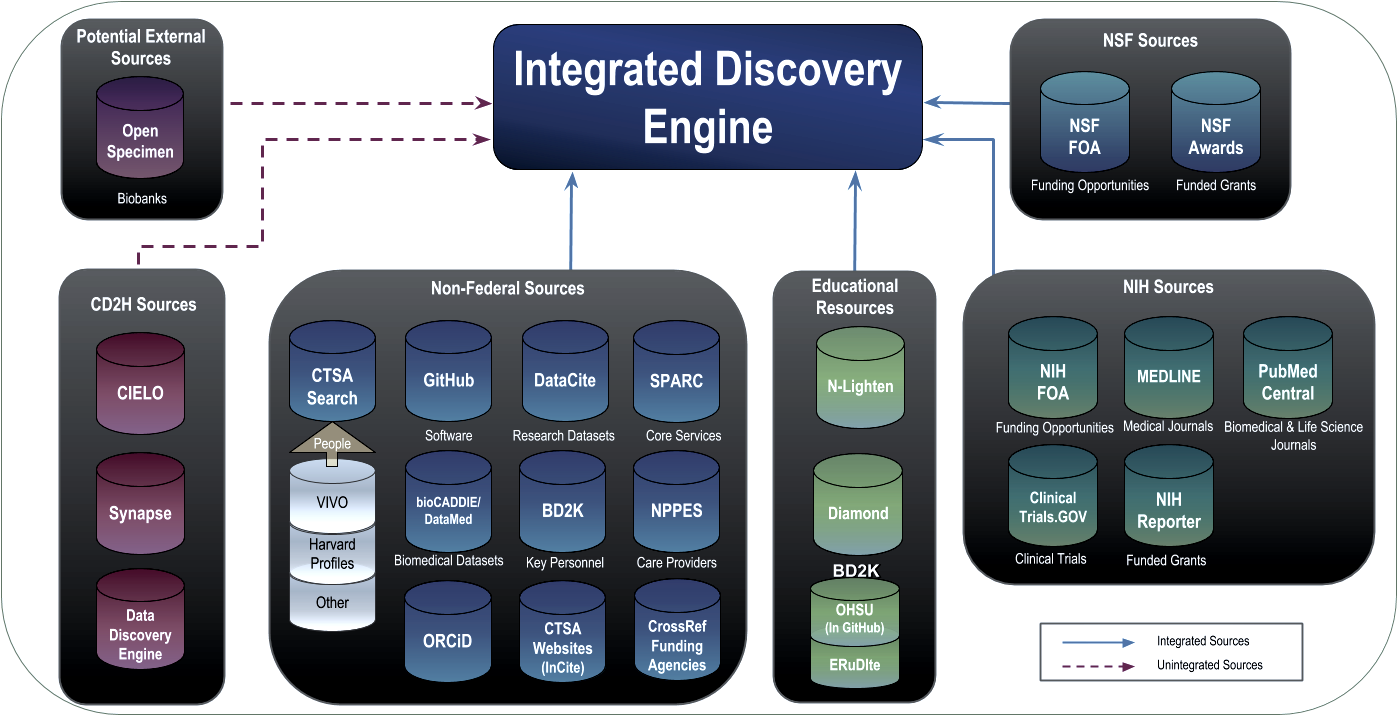
Project Description
Organizations expend substantial effort maintaining local databases of basically the same data—people, publications, grants—and the challenge of scholar disambiguation and longitudinal data collection/tracking remains unsolved. The Science of Translational Science platform performs large-scale data integration from a variety of sources using both structured and unstructured data. These data elements are indexed using semantic technologies for query and discovery. A user interface allows for query and exploration. Widgets are built to deliver context-specific content to CTSA hubs, CLIC Forums, the Compeititions review software, and more. We can use the Science of Translational Science Platform to demonstrate addressing the common CTSA need of longitudinal scholar data tracking and reporting.
A shared data environment in the form of a research data warehouse was strongly endorsed by participants at a previous PEA Community meeting. Collaborative population and maintenance of common data reduces local hub effort, improves data quality, and serves as an exemplar of collaborative activity for the CTSA and NIH programs. Substantial effort has been spent by hubs on this topic establishing priorities and developing manual and semi-automated processes, which helps to guide efforts toward automation.
The 4DM (Drug Discovery, Development, Deployment Map) project created by NCATS has generated substantial interest in understanding the interdependencies of translational research and the entities involved. The 4DM prototype was extended to incorporate relevant backing data from the data warehouse to display when selecting a vertex in the visualization graph. Ultimately, we can leverage these data for a variety of purposes at hubs, including workflows for improved data quality, process efficiency, automation, benchmarking, etc.